
کش چیست و سطوح L1 و L2 به چه معنی هستند؟
کش L1، L2 و L3 چیست، چه طور کار میکند و معماری و مقدار کش در سرعت پردازنده چه اثری دارد؟ این سوالات را در این مقاله پاسخ میدهیم و اهمیت کش را روشن میکنیم.
برگی از تاریخ، وقتی کش مهم و مهمتر میشود
اختراع کش یکی از مهمترین اتفاقات در دنیای پردازش است. تقریباً تمام پردازندههای پیشرفته مقداری کش دارند. حال ممکن است در هستههای ضعیف و کوچکی مثل Cortex-A5 آرم، مقدار و سرعت کش کمتر باشد و در پردازندههای رده بالای Core i7 اینتل، سرعت و مقدار این حافظهی مهم، بیشتر باشد.
امروزه حتی میکروکنترلرهای رده اول هم مقداری حافظه به عنوان کش دارند تا عملکردشان به مراتب بهتر شود. حافظهی کش هم مثل هر حافظهی فعال دیگری به توان الکتریکی نیاز دارد اما حتی توان مصرفی بیشتر هم جلوی استفاده از کش را نگرفته است.
نمونهای از آن Cortex-M4 آرم است. آرم را با تراشههای معروف گوشی و تبلت میشناسیم ولی میکروکنترلرهای اتمل مثل تراشهای که به صورت شماتیک در تصویر زیر میبینید هم حافظهی کش دارد:
در سالهای اولیهی شکلگیری تراشهها، سرعت حافظهها به نسبت سرعت و قدرت پردازشی پردازنده خوب و حتی زیاد بود. اما در دههی 1980 وضعیت کمکم برعکس شد. به این صورت که پردازندهها از نظر سرعت کلاک پیشرفت زیادی داشتند اما سرعت حافظه و تأخیری که در ارسال و اجرای فرامین وجود داشت، بهبود شدیدی پیدا نکرد و همین نکته آغازی برای تولد حافظهی کش شد.
بد نیست عملکرد پردازندهی اصلی و حافظه را در یک نمودار مقایسه کنیم. البته وظیفهی حافظه تأمین پهنای باند است و وظیفهی پردازنده، انجام محاسبات و پردازشهاست. بنابراین نمودار زیر واحدی ندارد، همه چیز به صورت مقیاس شده است:

در 1980 کشی در مایکروپراسزورها (همان ریزپردازنده یا به اصطلاح پردازنده) وجود نداشت اما در 1995، برخی پردازندهها به کش دو سطحی تجهیز شده بودند. امروزه هم کش سطح 3 و 4 را در پردازندهها میبینیم. نمودار فوق نشان میدهد که در سال 1980 اختلاف بین عملکرد کش و پردازنده کم بوده و هر دو را برابر واحد در نظر گرفتهایم. پس از آن به عنوان مثال در سال 1989 میبینیم که پردازندهی اصلی 10 برابر سریع شده ولیکن حافظه فقط 3 برابر بهبود پیدا کرده است. با این حساب روشن است که به نوعی حافظهی بهتر نیاز داریم که کش یا حافظهی میانجی نامیده شده است.
هدف از پیادهسازی کش، کاهش تأخیر و افزایش پهنای باند
مأموریت حافظهای به نام کش که گاهاً حافظهی میانجی هم ترجمه میشود در یک کلام این است:
حافظهی کش سرعت و پهنای باند بسیار بالایی دارد و تأخیر در دسترسی به محتوای آن بسیار کم است. از این رو اطلاعات مورد نیاز پردازنده را سریعتر و با تأخیر کمتر در اختیار آن میگذارد.
اهمیت تأخیر شاید کمی برای من و شما گنگ باشد اما وقتی به پردازندههای رده اول امروزی نگاه میکنیم که انبوهی از محاسبات پیچیده را تنها در کسری از ثانیه به پایان میرسانند به این باور میرسیم که پردازنده نباید برای دریافت دستورات و دادهها معطل شود. همه چیز باید سریع و بدون مکث در اختیار بخشهای پردازشی قرار بگیرد.
طرز کار کش
کش L1 یا سطح اول
کش حافظهی کوچکی است که فقط اطلاعاتی را شامل میشود که به احتمال زیاد پردازنده در مراحل بعدی کارکرد خود به آنها نیاز دارد. اینکه کدام دادهها و دستورات در کش قرار بگیرد به الگوریتمها پیچیده و نیز برخی پیشبینیها که با توجه به کدهای برنامه انجام شده، بستگی دارد. همانطور که گفته شد، هدف سیستم کش این است که اطلاعات مورد نیاز پردازنده، پیشاپیش روی کش گذاشته شده باشد و در هنگام نیاز، به سرعت در اختیار پردازنده قرار بگیرد.
به این حالت که دادهی مورد نیاز پردازنده پیشاپیش روی کش موجود باشد اصطلاحاً برخورد کش یا Cache Hit میگویند. اصطلاح هیت ریت یا نرخ برخورد هم به معنی درصد دفعاتی است که در هنگام مراجعه به کش، دادهی مورد نیاز روی آن وجود دارد.
برخی اوقات برعکس اتفاق فوق رخ میدهد یعنی وقتی پردازنده به کش مراجعه میکنید، دادههای مورد نیاز روی آن وجود ندارد و باید از حافظهی رم بارگذاری شود. در این صورت میگوییم Cache Miss رخ داده یا به عبارتی داده در کش موجود نیست.
کش L2 یا سطح دوم
وقتی اطلاعات در کش L1 موجود نباشد، بررسی کل سیستم برای یافتن اطلاعات زمان زیادی میگیرد و اینجا جایی است که کش L2 مفید واقع میشود. کش L2 کندتر از L1 است اما در عوض مقدار آن به مراتب بیشتر است و این یعنی اطلاعات بسیار زیادی روی آن جا میشود و نرخ برخورد را افزایش میدهد.
تصویر زیر هم به صورت شماتیک کش L2 را جدا از پردازنده و کش L1 آن نمایش داده که صد البته در تراشههای امروزی، حتی کش L3 و L4 هم جزئی از پردازنده هستند:
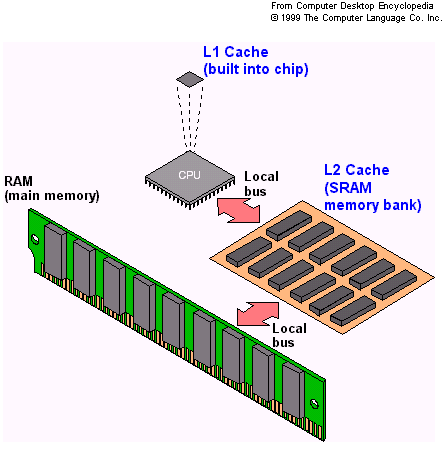
کش L2 در برخی پردازندهها حالت دربرگیرنده یا inclusive دارد به این معنی که هر چه در کش سطح 1 موجود است، عیناً در سطح دوم نیز نوشته شده است. برخی پردازندهها روش دیگری دارند که کش سطح دوم مستقل از کش سطح اول است و دادهی تکراری نداریم.
اگر اطلاعات مورد نیاز پردازنده روی کش سطح دوم هم وجود نداشته باشد، کش L3 وارد عمل میشود که باز هم ممکن است اطلاعات موردنظر روی آن موجود نباشد. این زنجیره به کش سطح چهارم، البته اگر وجود داشته باشد و سپس به حافظهی DRAM یا همان رم گسترش مییابد.
مقدار بهینهی کش
اینکه کش بیشتر باشد چیز بدی نیست اما مشکل اینجاست که کش بیشتر، سیلیکون بیشتری هم لازم دارد. تراشه بزرگتر میشود و توان مصرفی هم افزایش مییابد. شاید افزایش توان مصرفی و سطح تراشه زیاد نباشد اما به هر حال دو عامل منفی است. از همه مهمتر، هزینهی تولید تراشه است که بیشتر میشود.
از طرفی اگر تراشه را بزرگ نکنیم، کش بیشتر موجب میشود که سطح مفیدی که برای پردازنده و هستههای متعدد آن قابل استفاده است، کمتر شود.
نمودار زیر را بررسی کنید، در این نمودار رنگ بنفش نرخ برخورد کش L1 است که ثابت در نظر گرفته شده است. کش L2 از 1 تا 1024 کیلوبایت افزایش مییابد و با هر افزایش، نرخ برخورد کش L2 بیشتر میشود. اما به رقم 64 کیلوبایت دقت کنید، نمودار به نقطهای رسیده که دیگر افزایش کش L2 کمک زیادی به افزایش نرخ برخورد نمیکند.
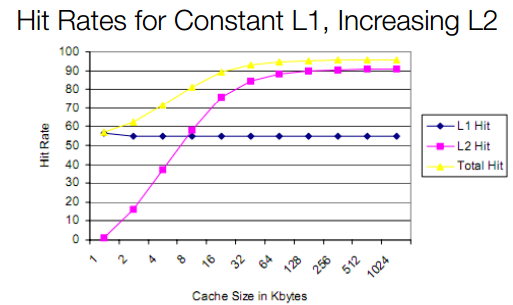
منطق سادهای پشت این قضیه نهفته است. هر پردازنده بسته به معماری و توان پردازشی خود، دادههای محدودی نیاز دارد که کش آنها را روی نیمکت ذخیرهها آماده نگه میدارد. درست مثل بازی فوتبال، اینکه نیمکت ذخیرهها بزرگ باشد لزوماً مفید نیست. شاید بسیاری از بازیکنهایی که پیشبینی شده مفید واقع میشوند، هیچ وقت به کار نیایند.
اندازهی نیمکت ذخیرهها یا به عبارت کامپیوتری مقدار کش L2 و L3 باید به درستی و به صورت بهینه گزینش شود.
تا یادمان نرفته بگویم که اینتل و ایامدی در پیشبینی دادههای مورد نیاز استاد شدهاند و مقدار نرخ برخورد، 50 درصدی که در مثال فوق ذکر شده نیست بلکه به ارقامی مثل 95 درصد! نزدیکتر است.
انواع نگاشت یا Mapping
میخواهیم روشهای نگاشت دادههای رم به کش را بررسی کنیم. اما در ابتدا ببینیم دادههای رم و کش چه ارتباطی با هم دارند.
مفهوم نگاشت یا Mapping در کش چیست؟
پاسخ این است که میخواهیم برخی از قسمتهای رم را در کش نگه داریم که سرعت دسترسی به آن دادهها یا دستورات را افزایش دهیم. روشی که برای انتخاب آن قسمت از کش برمیگزینیم، نوع نگاشت را مشخص میکند.
به بیان دیگر نگاشت است که مشخص میکند دادههای هر بخش از حافظهی رم در کدام یک از بلوکهای کش نگهداری میشود.
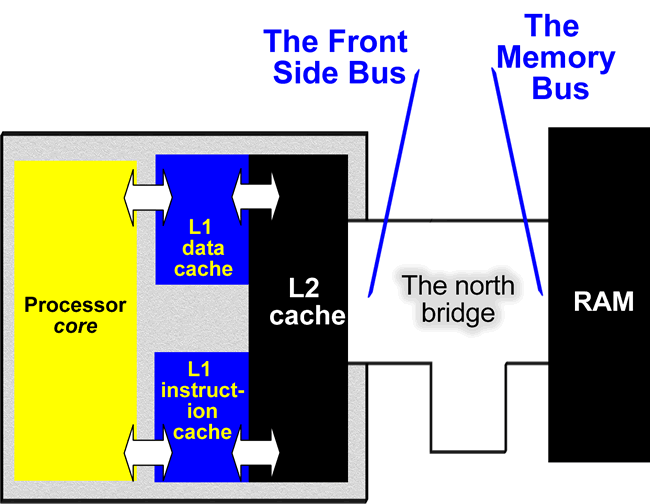
سه نوع نگاشت رم به کش
سه نوع روش مرسوم در این مورد وجود دارد که به نامهای نگاشت کامل یا Fully Associative، نگاشت مستقیم یا Direct-Mapped و نگاشت شرکتپذیر جمعی یا Set-Associative مشهورند.
هر CPU بخش خاصی از RAM را با tag مشخص میکند که tag نمایندهی همهی مکانهای حافظه است که میتوانند به یک بلاک خاص از کش نگاشت داده شوند. اگر کش مورد نظر دارای نگاشت کامل باشد، به این معنی است که هر بلاک رم میتواند در هر بلاک کش نوشته شود. مزیت این روش این است که نرخ برخورد بسیار زیاد میشود؛ اما به علت اینکه CPU باید تمام کش را برای جستجوی یک بلاک بگردد، زمان جستجو به شدت زیاد میشود و انتخاب بهینهای نیست.
در نوع دیگر کش که با نگاشت مستقیم کار میکنند، هر بلاک کش میتواند یک و فقط یک بلاک از حافظهی اصلی را نگه دارد. این نوع کش سرعت بسیار بیشتری را دارد. اما به علت رابطهی یک به یک با مکانهای حافظهی اصلی، نرخ برخورد کمی دارد.
این دو حالت را در تصویر زیر بررسی کنید، حالت سمت چپ به این معنی است که برای پیدا کردن دادهی موردنیاز تنها باید در بلوک 4 رم جستوجو صورت بگیرد و با توجه به تگ به آدرس موردنظر مراجعه شود.
در کش با نگاشت شرکت پذیر جمعی که حالت وسطی در تصویر فوق است، نحوهی کار به صورت زیر است:
فرض کنید کش 2 راههی شرکتپذیر یا اصطلاحاً cache 2-Way-Assosiative باشد. در این صورت هر بلوک از حافظهی رم میتواند به یکی از 2 بلوک خاص کش که معین شده مربوط شود یا اصطلاحاً نگاشت یابد. حال اگر نگاشتی به صورت 8 راههی شرکتپذیر باشد، همین رابطه بین 8 بلوک رم و 8 بلوک کش وجود دارد.
پردازندههای مختلف از نظر نگاشت کش هم متفاوت هستند. مثلاً هستههای Pile Driver ایامدی نگاشت 2 راهه دارند اما هستههای استیم رولر همین کمپانی، کش L1 با نگاشت 3 راههی شرکتپذیر را مورد استفاده قرار میدهند. در ادامه این موضوع را بیشتر بررسی و البته مقایسه میکنیم.
در شکل زیر میتوان دید که نرخ برخورد چگونه با روش شرکت پذیر جمعی افزایش مییابد. کش L1 در اندازهی 1 کیلوبایت تا 1 مگابایت محور افقی را تشکیل داده و درصد برخورد محور عمودی است. به یاد داشته باشید که نرخ برخورد به برنامهی در حال اجرا هم بستگی دارد و لذا برنامههای مختلف نرخ برخورد متفاوتی را نشان میدهند.
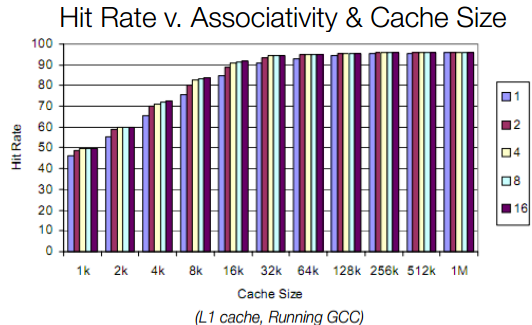
بررسی نمودار فوق نشان میدهد که اگر کش L1 نگاشت 2 الی 4 راههی شرکتپذیر داشته باشد، درصد برخورد بهینه است. بیش از آن درصد برخورد بیشتر میشود اما همانطور که اشاره شد، زمان بیشتری هم برای جستوجوی بلوکهای متعدد لازم است که در مجموع به نفع عملکرد کلی سیستم نیست.
چرا کشهای حافظه بزرگتر شدهاند؟
کش L3 پردازندهی هسول-اکستریم 8 هستهای که چندی پیش بررسی کردم، 20 مگابایت بود که نسبت به سالهای اخیر اینتل، یک رکورد محسوب میشود. اما از آن جالبتر معماری Crystallwell برخی هسولیهاست که در آن از eDRAM به عنوان کش L4 استفاده شده است. ظرفیت آن هم رقم باورنکردنی 128 مگابایت است و البته فعلاً فقط در همین اندازه استفاده شده است. قبلاً در نشریات خواندهام که در برودول هم قرار است از L4 استفاده شود ولیکن در تمام مدلها اینگونه نیست.
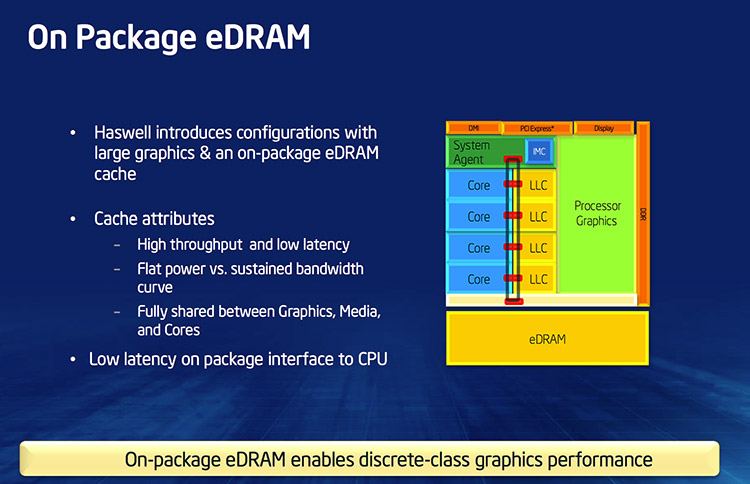
در اکسباکس وان هم 32 مگابایت حافظهی ویژه در نظر گرفته شده است اما چطور و به چه منظور؟

در واقع فقط اینتل نیست که به افزایش کش پرداخته، ایامدی هم در پردازندهی کنسول معروف اکسباکس وان مایکروسافت از کش اضافی استفاده کرده است. البته اینتل از یک نظر متمایز است؛ کش L4 اینتل هر دادهای که از L3 دستور خروج دارد را تحویل میگیرد و در واقع یک کش کارآمد است. این کش هم به پردازندهی اصلی و هم به پردازندهی گرافیکی مجتمع که معمولاً کش بیشتری هم نیاز دارد، کمک میکند. البته اگر کارت گرافیک مجزا داشته باشید، تمام آن به پردازندهی اصلی تخصیص مییابد.
در Xbox One به لطف حافظهی 32 مگابایتی eSRAM پهنای باند حافظهی داخلی تراشه 102 گیگابایت بر ثانیه افزایش یافته و لذا پهنای باند مجموعهی حافظهی رم و داخلی، تقریباً مثل کنسول PS4 است. البته PS4 از نظر توان پردازش گرافیک، 1.5 برابر سریعتر است که ارتباط زیادی به کش ندارد.
پهنای باند
اینتل در مورد این کش اعلام کرده که پهنای باند یک طرفهی 50 گیگابایت بر ثانیهای و در مجموع 100 گیگابایت بر ثانیهای دارد. زمان دسترسی هم 30 تا 32 نانوثانیه است. سرعت بیشینهی آن 1.6 گیگاهرتز است و با این تفاسیر کش جالبی است. اما چه قدر موثر است و آیا ارزش داشته که اینتل از این کش استفاده کند و هزینهی تراشه را افزایش دهد؟
[stextbox id="grey"]جالب است بندانید که برای هر بیت کش، 6 ترانزیستور لازم است. 4 مگابایت معادل 32 مگابیت کش، به 32 میلیون ضربدر 6 ترانزیستور یعنی 192 میلیون ترانزیستور نیاز دارد که بخشی زیادی از تراشه را شامل میشود چرا که تراشههای امروزی معمولاً 1 الی 2 میلیارد ترانزیستور دارند. به جای کش 128 مگابایت L4 میتوان هستههای پردازندهی اصلی و گرافیکی را بیشتر کرد، واحد پیشبینی شاخهها را بهبود داد و مواردی از این دست به تراشه اضافه کرد.[/stextbox]
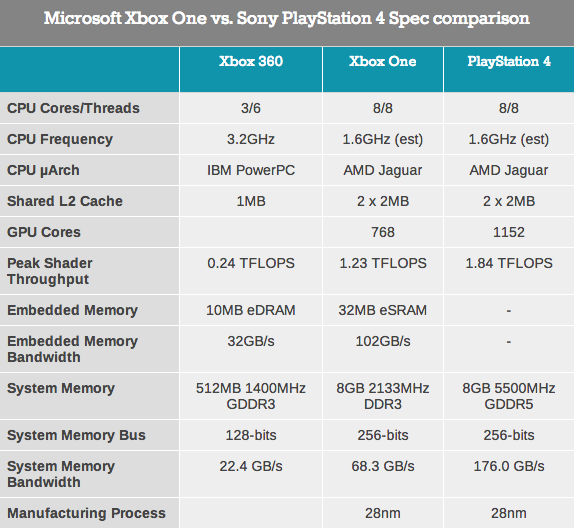
ابتدا پهنای باند کشها را مقایسه میکنم. در بنچمارک SANDRA نتیجهی مقایسه پهنای باند کش L1 تا L4 سه معماری هسول، آیوی بریج و از آن قدیمیتر سندی بریج به صورت زیر است:
کش L1 کاملاً خودنمایی میکند، پهنای باند این کش کوچک اینتلی بیش از هر کش دیگری است. پهنای باند حافظهی DDR3 و حتی DDR4ها که به تازگی معرفی شدهاند، حتی در حالت 4 کاناله هم زیر 80 گیگابایت بر ثانیه است حال آنکه L1 در معماری 2 سال پیش اینتل یعنی سندی بریج، به تنهایی پهنای باند 320 گیگابایت بر ثانیهای داشته است. فرآیند پردازش مثل کپی کردن فیلمهای 50 گیگابایتی نیست بلکه بسیار پیچیدهتر است به طوری که با پهنای باند L1 میتوان اطلاعات 80 دیویدی معمولی را در تنها یک ثانیه جابجا کرد.
تأخیر در دسترسی به سطوح مختلف کش در اینتلیهای پرچمدار
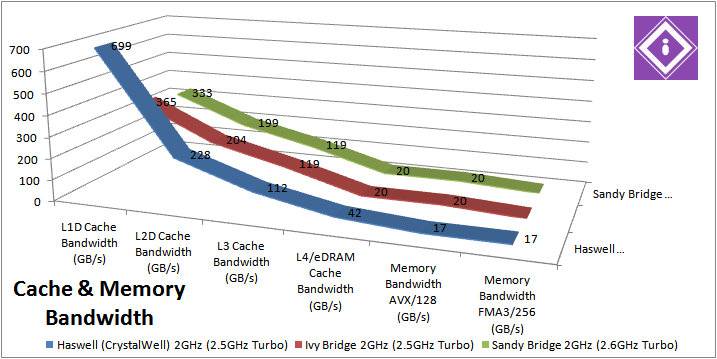
حال به تأخیر نگاهی میاندازیم. هسول و آیوی بریج به اضافهی یک پردازندهی ویژه که کش L4 دارد مدنظر است. در نمودار زیر رنگ قرمز همان پردازندهای است که گرافیک پیشرفتهتر آیریس را دارد و کش L4 یا همان eRAM در آن استفاده شده است.
مشاهده میکنید که تأخیر در دسترسی به بخشهای مختلف حافظه کاملاً نمایانگر سطوح کش است. مثلا وقنی به 2 تا 32 کیلوبایت ابتدایی نیاز است، تأخیر کمتر از 6 نانوثانیه است. در بخش دوم وقتی به 32 الی 256 کیلوبایت سر میزنیم، تأخیر حدود 16 نانوثانیه است. این کش سطح دوم است.
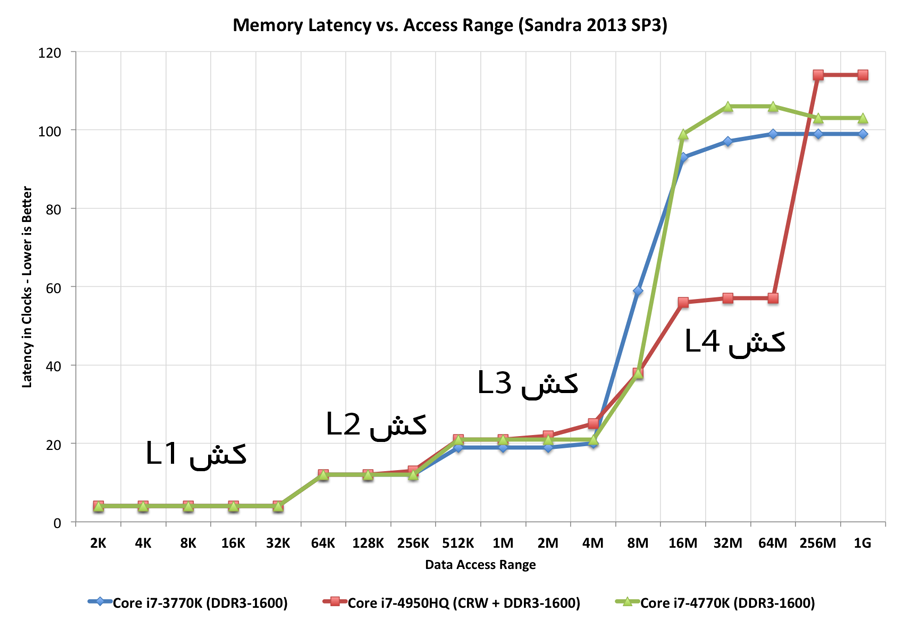
برای مقایسه آیفون 6 اپل هم به عنوان یکی از بهترین تراشههای موبایل آورده شده است:
کش سطح سوم هم تأخیری حدود 20 نانوثانیه دارد و پس از آن دو مدل Core i7-3770K و Core i7-4770K ناگهان جهش شدیدی دارند. علت این است که دسترسی به رم تأخیر به مراتب بیشتری ایجاد میکند. اما Core i7-4950HQ میتوان با تأخیری در حدود 58 نانوثانیه به کش L4 خود دسترسی داشته باشد. این وضعیت تا رسیدن به 128 مگابیت کم و بیش ادامه دارد و از آن پس باید تأخیر زیاد برای دسترسی به رم را تجربه کرد.
جایی که کش زیاد خوب نیست!
یک مثال بسیار ساده میزنم که البته نمود واقعی ندارد و صرفاً مثالی است که نشان میدهد کش بیشتر همیشه هم خوب نیست.
همان پردازندهی Core i7-4950HQ اینتل را در نظر بگیرید. فرض کنید پردازنده به 10 بار خواندن داده نیاز دارد. اگر هر 10 بار داده در L1 وجود داشته باشد و به عبارتی هیت ریت L1 برابر با 100 درصد باشد، 10 ضربدر 6 نانوثانیه زمان لازم است.
حال L1 را با هیت ریت 90 درصد تصور کنید. 9 بار و در مجموع 54 ثانیه زمان لازم است که 9 دادهی اول در اختیار هستههای پردازشی قرار گیرند و برای دادهی دهم که فرضاً روی L2 موجود است، با توجه به نمودار فوق زمانی در حد 16 نانوثانیه لازم است. بنابراین در مجموع 54+16 یا 70 نانوثانیه زمان لازم است.
مشخص است که معماری کش و نرخ برخورد بسیار مهم است و صرفاً نمیتوان با افزایش کش مشکلات را حل کرد. مشکل اصلی تأخیر نسبتاً زیاد کش سطوح 2 به بعد است.
در بنچمارکهایی که از Core i7-4790K دیدهام به نظر میرسد که عملکرد کش بهبود پیدا کرده ولی اثر آن در برخی بنچمارکها نمود پیدا میکند. در حقیقت فعلاً اینتل یا ایامدی به نقطهای نرسیدهاند که از کش L4 استفادهی بهینهای ببرند و این کار بیشتر برای آینده تراشهها لازم است. در آیندهی نزدیک شاید hUMA ایامدی و به طور کلی HSA اثر کش مشترک و عظیم L4 را بسیار بیشتر کند.
نکتهی دیگری که قبلاً هم به آن اشاره کردم، هیت ریت فوقالعاده بالای L1 است. در دنیای واقعی ارقام کمتر از 90 درصد یک فاجعه به حساب میآیند چرا که با توجه به مثالی که زدم، عملکرد به شدت افت پیدا میکند. به هر حال L1 سریعترین حافظهی موجود روی سیستم است و علیرقم مقدار بسیار ناچیز، تأثیر شدیدی روی سرعت کلی پردازش میگذارد.
فلسفهی ضعف FXهای سری بولدوزر AMD با 8 هسته
از هیت ریت سخن گفتیم و مثالی زدیم که اهمیت معماری کش را روشن کرد. شاید به همین علت است که بولدوزرهای 8 هستهای AMD که کش L2 و L3 مجموعاً 16 مگابایتی دارند، در برابر هسول رفرشی که فقط 8 مگابایت کش L3 دارد، ناتوان ظاهر میشوند. البته نمیدانم چند درصد از فاصلهی 4 هستهایهای هسولی و بولدوزرهای ایامدی به خاطر طراحی و معماری کش است اما قطعاً بخشی از آن به کش مربوط میشود.
مشخصات کش پردازندههای ایامدی را ببینید:
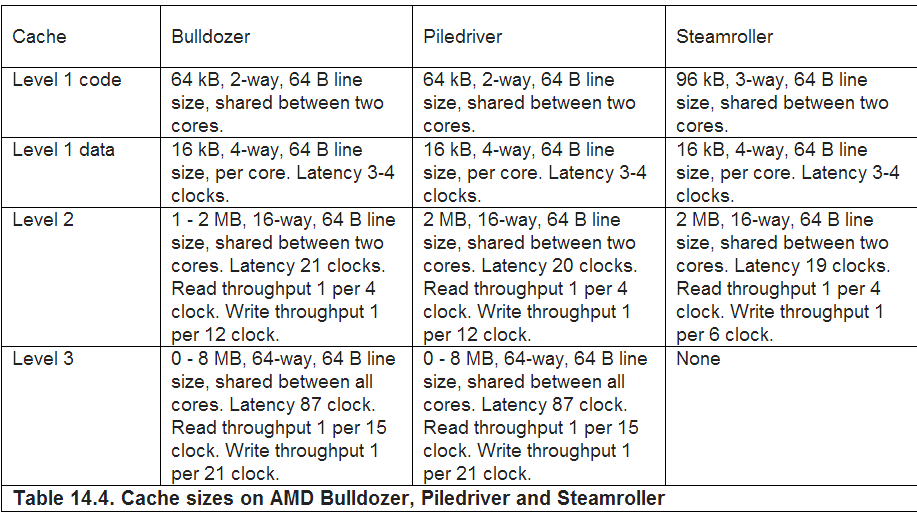
مورد دیگری که روی کارایی این پردازندهها اثر سوء گذاشته، Contention یا درگیر تردهای پردازشی بر سر استفاده از بخش خاصی از کش است. هستهها و تردهای پردازشی متعدد ممکن است نیاز به نوشتن داده روی یک بخش فضای حافظه داشته باشند. این درگیری به نفع فرآیند پردازش نیست و عملکرد را کاهش میدهد.
مثلاً Opteron 6276 را در نظر بگیرید که از هستههای بولدوزر بهره میگیرد. اگر محاسبات تک تردی صورت بگیرد یعنی فرضاً SQL Server مایکروسافت اجرا شود، هیت ریت 99 درصد است. اما وقتی Cinebench 11.5 به صورت چند تردی عمل کند، هیت ریت 97 درصد میشود. همین 2 درصد افت نرخ برخورد، سرعت کار را بسیار کاهش میدهد:

در بولدوزر این مشکل به نظر جدی میرسید، در پایل درایور هم تکرار شد و حتی حالا در استیمرولر هم ردپای مشکل مشهود است. البته ایامدی هم متوجه مشکل شده و کش L1 را از 64 به 96 کیلوبایت ارتقا داده (منظور کش دستور یا کد است، نه کش داده) و نیز آن را به صورت سه راهه شرکتپذیر طراحی کرده است.
آیندهی کش یا حافظهی میانجی
با اشارهای که به کش L4 در کریستال ول اینتل و نیز به زودی در برودول شد، به نظر میرسد که قاعدهی کلی یک سطح جدید کش در هر 10 سال، همچنان پابرجاست. در 1980 کش وجود نداشت، در 1995 دو سطح کش ظهور کرد و حالا در 2014، کش L4 هم در مدلهایی کم و خاص پیادهسازی شده است.
محققین و طراحان پردازنده همواره روی کش مشغول به کار هستند تا به هر روش ممکن، کارایی آن را بیش از پیش افزایش دهند و تأخیر و پهنای باند و عامل مهمی به نام نرخ برخورد را به وضعیت بهتری برسانند.
البته استراتژی AMD هم در نوع خود بسیار جالب است. در hUMA و به طور کلی HSA دسترسی به حافظه یک معماری و روش جدید دارد که ممکن است آیندهی پردازش و صد البته کش را متحول کند. ایامدی هم مثل سایر تولیدکنندگان تراشه به نوعی در مقابل اینتل بزرگ ناتوان ظاهر شده ولیکن HSA میتواند یک راه حل نرمافزار و سختافزاری بهینه و مفید باشد.
اینتوتک
البته پیشاپیش بگم رسول شیری همش رو ننوشته. بیشترش رو خودم نوشتم. زحمت عکس چینی هم با بنده بوده!
😀
حالا متوجه میشم چرا اینتل با کشی که نصفه هم رده های amd داره میتونه عملکرد بهتری داشته باشه!
اینتل تو کش و معماری کش هر کم و کاستی جای دیگه داره، جبران میکنه.
تو بنچ مارک سان اسپایدر که اپل همش اول میشه، اینتل همش در صدره.
علاوه برا این توی لیتوگرافی هم یه یکی دو پله از بقیه جلوتره!
توی متن در باره اینکه چرا باید حجم کش مقدار مشخصی باشه توضیح داده شد اما در مورد اینکه چرا باید سرعت ها بیشتر باشه چیزی گفته نشد.اصلا چرا به جای 3 سطح مختلف یه از سطح با سرعت بالا L1 استفاده نمیشه؟!
منطقا تاخیر کمتری خواهیم داشت!
دقیق که نمیدونم اما به نظرم پهنای باس محدوده. نمیشه هسته به کل مثلاً رم که به شکل کش L1 پیاده سازی شده دسترسی داشته باشه. اصلاً اگه میشد، رم و کش حذف میشد و هارد میچسبید به پردازنده. یه هرم دسترسی لازم بوده حتما.
راستش تنها چیزی که به ذهن خودم میرسه قیمته! وگرنه به قول شما یه حافظه به سرعت و پهنای باند L1 میساختن.سیستم کلی ساده هم میشد!