
گیگافلاپس به معنی قدرت خام پردازش اعشاری است و معمولاً قدرت خام پردازنده اصلی یا CPU و یا قدرت پردازشی کارت گرافیک برای انجام محاسبات اعشاری ۳۲ بیتی (به اختصار FP32) را توصیف میکند. FP64 یا محاسبات اعشاری با دقت مضاعف، در محاسبات دقیقتر کاربرد دارد.
در ادامه به مفهوم گیگافلاپس، FP32 و FP64 و اکستنشنهای برداری که در پردازندههای اینتل و AMD وجود دارد و با نام SSE و AVX و FMA شناخته میشود، میپردازیم.
گیگافلاپس چیست؟ آشنایی با تفاوت FP32 و FP64
فلاپس مخفف Floating Point Operations Per Second و به معنی تعداد اعمال محاسبهی اعشاری در ثانیه است و در حقیقت واحدی استاندارد برای بیان قدرت پردازشی است. گیگافلاپس (یک میلیارد عمل اعشاری در ثانیه) و ترافلاپس (یک بیلیون یا 10 به توان 12 عمل اعشاری در یک ثانیه) در بیان قدرت پردازشی پردازندههای امروزی، به کار میرود.
محاسبهی صحیح یا اینتیجر به این معنی است که اعداد بخش اعشاری ندارند و یا دقت زیادی لازم نیست. 16 بیت برای هر عدد (معادل 2 بایت) به کار میرود. اعداد اعشاری یا در واقع اعداد دارای بخش اعشاری (Floating Point)، میتوانند دقت واحد (32 بیت یا 4 بایت برای هر عدد) و یا دقت مضاعف یا دو برابر یا double precision که معمولاً به آن دابل میگویند (برای هر عدد 64 بیت) داشته باشند. بنابراین محاسبهی اعشاری میتواند به صورت 32 بیتی یا 64 بیتی باشد و البته حالت 16 بیتی هم در گوشیها و پردازش اعشاری سبکتر، کاربرد دارد.
در اینتوتک به سه حالت اشاره شده به اختصار FP32 و FP64 و FP16 میگوییم. گیگافلاپس بدون ذکر دقت محاسبه، به معنی FP32 است.
پردازندههای گرافیکی سادهای که گیمرها استفاده میکنند، برای محاسبات اعشاری 32 بیتی طراحی شدهاند و معمولاً قدرت محاسبات اعشاری با دقت مضاعف (همان FP64)، کسری از قدرت محاسبات اعشاری با دقت واحد (FP32) است. مثلاً در GTX 780 Ti قدرت پردازشی FP64 معادل 1/24 قدرت محاسبات 32 بیتی است.
کاربرد FP64 در مواقعی است که پردازندهی گرافیکی برای اعمال محاسباتی خاص و دقیق به کار میرود. به عنوان مثال در یک بازی بهینه، موقعیت دقیق اجسام، پرتوهای نور و سایهها، برخورد اجسام و محاسبات فیزیکی، شبیهسازی بسیار دقیق جریان مایعات، سطح آب و حرکات مو و ... لازم نیست. کافی است تخمینی از تمام موارد لحاظ شود و تصویر نهایی رندر شود. به چند کاربرد ساده توجه کنید:
کاربردهای خاص محاسبات اعشاری با دقت مضاعف یا FP64
Ray Tracing یا محاسبهی مسیر پرتوی نور
بنچمارک LuxMark برای محاسبهی مسیر باریکههای نور، از OpenCL و قدرت بسیار بالای پردازندهی گرافیکی بهره میگیرد. Ray Tracing یا محاسبهی مسیر پرتوی نور، یکی از کاربردهای گستردهی پردازندهی گرافیکی در سالهای اخیر بوده و در کامپیوترهای ویژهی رندرینگ، معمولاً از کارت گرافیکهایی با FP64 بالاتر در حد کوآدروهای انویدیا و فایرپروهای ایامدی استفاده میشود. تسلا FP64 بسیار بالایی دارد و در FP32 نیز درخشان ظاهر میشود، لذا در محاسبات توسط نرمافزارهای مهندسی خاص، کاربرد دارد و برای صرفاً رندرینگ، گزینهی خوبی نیست.

تشخیص چهره
برای لاگین کردن میتوان از تشخیص چهرهی کاربر استفاده کرد. به جای استفادهی صرف از هستههای پردازندهی اصلی، میتوان محاسبات دقیق اعشاری را به کمک پردازندهی گرافیکی انجام داد.
شبیهسازی فیزیکی و دینامیکی ذرات
در بازیها نیازی به فیزیک و دینامیک بسیار دقیق نداریم اما در شبیهسازی دقیق دنیای واقعی به دقت بالا نیاز داریم.
به عنوان مثال در محاسبهی حرکت یک پرتابه نظیر موشک، برخورد ذرات کوچک و صلب (جامد)، تحلیل نیرو، تنش و کرنش در اجسام، تحلیل حرکات پیچیدهی سیالات (آب و هوا) و ... به دقت بالایی نیاز است و طبعاً FP64 بالاتر، انتخاب خوبی است.

مقایسهی سه کارت گرافیک ویژهی بازی، محاسبه و بازی و اختصاصی برای محاسبات سنگین
انویدیا با تراشهی K110 که با توجه به حرف K معماری کپلر (سری 600 و 700) در آن پیادهسازی شده، سه کارت گرافیک GTX 780 Ti و GTX Titan Black و Tesla K40C را طراحی و تولید کرده است. بنابراین هر سه دارای 15 واحد SMX هستند و 192 هستهی پردازش چندمنظوره که در زبان انویدیا CUDA نام دارد، در هر SMX قرار گرفته است. بنابراین 2880 هسته در هر سه مدل وجود دارد. سرعت هستهها اندکی متفاوت است اما آن را نادیده میگیریم.
در محاسبات اعشاری 32 بیتی یا همان FP32، تایتان بلک و GTX 780 Ti حدود 5.1 ترافلاپس قدرت خام دارند ولیکن Tesla K40C قدرت 4.3 ترافلاپسی دارد و در نتیجه ضعیفتر است.
در محاسبات اعشاری با دقت مضاعف یا همان FP64، کارت گرافیک Tesla K40C یک سوم قدرت محاسباتی FP32 خود را ارایه میکند حال آنکه GTX 780 Ti فقط 1/24 آن را در اختیار کاربر قرار میدهد. بنابراین تسلای اشاره شده، تقریباً 7 برابر سریعتر است! Tesla K40C به ازای هر سه هستهی محاسبات 32 بیتی، یک واحد محاسبهی اعشاری 64 بیتی ویژه دارد، لذا بسته به نیاز میتوان FP32 با سرعت بالاتر و یا FP64 با سرعت یک سوم را در دستور کار قرار داد.
تایتان بلک حالتی میانه دارد، اگر کاربر حالت TCC را فعال کند، قدرت محاسبات اعشاری 64 بیتی، یک سوم حالت 32 بیتی است و البته در این حالت، محاسبات 32 بیتی با سرعت پایینتری انجام میشود.
در معماری مکسول انویدیا (سری 900) نسبت 1/24 کپلر به 1/32 کاهش یافته است و کارت گرافیکها بیشتر برای اجرای بازیها بهینه هستند تا محاسبات سنگین. AMD از این نظر وضعیت بهتری دارد و نسبت 1/3 و 1/4 و 1/8 و یا 1/16 در محصولات مختلف دیده میشود و یکی از علل بالاتر بودن توان مصرفی محصولات AMD این است که واحدهای پردازشی کمتری غیرفعال هستند.
مقایسهای بین محصولات جدید دو غول گرافیکی از نظر FP32 و FP64 داشته باشیم:
| مقایسه FP32 و FP64 کارت گرافیکهای AMD و انویدیا | |||
|---|---|---|---|
| کارت گرافیک |
FP32 گیگافلاپس |
FP64 گیگافلاپس |
نسبت FP64 به FP32 |
| Radeon R9 295X2 | 11264 | 1408 | FP64 = 1/8 FP32 |
| Radeon HD 7990 | 7782 | 1946 | FP64 = 1/4 FP32 |
| GeForce GTX Titan Black | 5645 | 1881 | FP64 = 1/3 FP32 |
| GeForce GTX 690 | 5622 | 234 | FP64 = 1/24 FP32 |
| Radeon R9 290X | 5632 | 704 | FP64 = 1/8 FP32 |
| GeForce GTX 780 Ti | 5345 | 223 | FP64 = 1/24 FP32 |
| Radeon HD 6990 | 5099 | 1276 | FP64 = 1/4 FP32 |
| GeForce GTX 980 | 4981 | 156 | FP64 = 1/32 FP32 |
| Radeon R9 290 | 4849 | 606 | FP64 = 1/8 FP32 |
| GeForce GTX Titan | 4709 | 1523 | FP64 = 1/3 FP32 |
| Radeon HD 7970 GHz | 4301 | 1075 | FP64 = 1/4 FP32 |
| GeForce GTX 970 | 3920 | 122 | FP64 = 1/32 FP32 |
| GeForce GTX 780 | 4156 | 173 | FP64 = 1/24 FP32 |
| Radeon R9 280X | 4096 | 1024 | FP64 = 1/4 FP32 |
| Radeon R9 280 | 3344 | 836 | FP64 = 1/4 FP32 |
| Radeon HD 7950 Boost | 3315 | 828 | FP64 = 1/4 FP32 |
| GeForce GTX 770 | 3210 | 134 | FP64 = 1/24 FP32 |
| GeForce GTX 680 | 3090 | 129 | FP64 = 1/24 FP32 |
| Radeon HD 7950 | 2867 | 717 | FP64 = 1/4 FP32 |
| Radeon HD 5870 | 2720 | 544 | FP64 = 1/5 FP32 |
| Radeon HD 6970 | 2703 | 675 | FP64 = 1/4 FP32 |
| Radeon R9 270X | 2688 | 168 | FP64 = 1/16 FP32 |
| Radeon HD 7870 | 2560 | 160 | FP64 = 1/16 FP32 |
| GeForce GTX 590 | 2488 | 311 | FP64 = 1/8 FP32 |
| GeForce GTX 670 | 2460 | 102 | FP64 = 1/24 FP32 |
| GeForce GTX 660 Ti | 2460 | 102 | FP64 = 1/24 FP32 |
| Radeon R9 270 | 2368 | 148 | FP64 = 1/16 FP32 |
| GeForce GTX 760 | 2258 | 94 | FP64 = 1/24 FP32 |
| Radeon HD 6950 | 2253 | 563 | FP64 = 1/4 FP32 |
| Radeon HD 5850 | 2088 | 417 | FP64 = 1/5 FP32 |
| Radeon R7 260X | 1971 | 123 | FP64 = 1/16 FP32 |
| Radeon R7 265 | 1894 | 118 | FP64 = 1/16 FP32 |
| GeForce GTX 660 | 1882 | 78 | FP64 = 1/24 FP32 |
| Radeon HD 7790 | 1792 | 128 | FP64 = 1/14 FP32 |
| Radeon HD 7850 | 1761 | 110 | FP64 = 1/16 FP32 |
| GeForce GTX 580 | 1581 | 197 | FP64 = 1/8 FP32 |
| Radeon R7 260 | 1536 | 96 | FP64 = 1/16 FP32 |
| GeForce GTX 650 Ti Boost | 1505 | 62 | FP64 = 1/24 FP32 |
| GeForce GTX 650 Ti | 1425 | 60 | FP64 = 1/24 FP32 |
| GeForce GTX 570 | 1405 | 175 | FP64 = 1/8 FP32 |
| GeForce GTX 750 Ti | 1388 | 43 | FP64 = 1/32 FP32 |
| Radeon HD 7770 GHz | 1280 | 80 | FP64 = 1/16 FP32 |
| Radeon R7 250X | 1280 | 80 | FP64 = 1/16 FP32 |
| GeForce GTX 750 | 1110 | 34 | FP64 = 1/32 FP32 |
| GeForce GTX 650 | 812 | 33 | FP64 = 1/24 FP32 |
| Radeon R7 250 | 806 | 50 | FP64 = 1/16 FP32 |
| Radeon R7 240 | 500 | 31 | FP64 = 1/16 FP32 |
گیگافلاپس برابر اما عملکرد متفاوت در بازیها!
عبارت فوق در چند سال اخیر نقل محافل مقایسه AMD و انویدیا بوده است. در کارت گرافیکهای ایامدی معمولاً قدرت پردازشی FP32 بالاتر است ولیکن چیزی که در بازیها و بنچمارکها تجربه میکنیم، مشابه محصولات انویدیا با قدرت پردازشی کمی پایینتر است. سوال این است:
چرا برابر بودن گیگافلاپس به معنی اجرای بازیها با سرعت برابر نیست؟
دو کارت گرافیک با گرافیک مشابه از نظر گیگافلاپس، معماری یکسانی ندارند.
ممکن است یک فرآیند پردازشی متشکل از دستورهایی باشد که در کامپیوتر اول طی 1000 عمل اعشاری تکمیل شوند و در کامپیوتر دوم، طی 1200 عمل اعشاری. در حقیقت معماری هستههای پردازش گرافیک در کامپیوتر اول به گونهای است که در آن واحد، بخشهای بیشتری فعال هستند و اعمال کوچک با موازیسازی بهتری صورت میگیرد.
علت دیگر که شاید کمتر مهم باشد این است که در یک فرآیند پردازشی مجموعهای از محاسبات اعشاری و صحیح نیاز است. طبعاً مقایسه کردن گیگافلاپس ارتباط مستقیمی با قدرت محاسبات صحیح ندارد و صرفاً نباید به گیگافلاپس توجه کرد.
با توجه به مباحث فوق، در اینتوتک معمولاً به جای قدرت پردازشی از قدرت پردازشی خام با واحد گیگافلاپس استفاده میشود، بهینه بودن معماری قدرت خام را به خروجی خوب در بنچمارکها و بازیها تبدیل خواهد کرد.
در نهایت اگر بخواهیم کارت گرافیکها را مقایسه کنیم، علاوه بر گیگافلاپس باید نوسان سرعت کلاک را هم لحاظ کنیم. کارت گرافیکها و پردازندههای گرافیکی که توان طراحی حرارتی یا به اختصار TDP بالاتری دارند، در بیشتر مواقع و حتی در حالتی که تراشه کاملاً داغ شده، تلاش میکنند سرعت را در حد سرعت بوست حداکثری حفظ کنند. اما در مدلهای کممصرف و کوچکتر، سرعت به راحتی افت میکند.
به عنوان مثال میتوانید R9 Nano و R9 Fury X را مقایسه کنید، سرعت کلاک حداکثری یکسان است اما توان مصرفی 100 وات متفاوت است و طبعاً سرعت کلاک متوسط در کارت گرافیک R9 Nano به جای 1 گیگاهرتز، در حد 0.8 یا 0.75 گیگاهرتز است.
با توجه به دو مقولهی اشاره شده، گیگافلاپس معیاری کلی برای مقایسهی کارت گرافیکهای متنوع و پردازندههای گرافیکی کممصرف در گوشیها و تبلتهاست. در واقع اگر دو کارت گرافیک یا پردازندهی گرافیکی خاص، TDP برابر و گیگافلاپس یکسان داشته باشند، عملکردشان در بنچمارکهای مختلف، نهایتاً 20 یا 25 درصد متفاوت خواهد بود. به عنوان مثال گرافیک مجتمع اینتل در اسکایلیک، تقریباً با مکسول 2 انویدیا (سری 900 لپتاپی) برابری میکند و هر دو 15 یا 20 درصد بهتر از Radeon R300M ایامدی برای لپتاپها هستند.
برای مقایسهی مدلهای مختلف پردازندههای گرافیکی به صفحهی کارت گرافیکها در اینتوتک مراجعه فرمایید.
پردازندهی اصلی اینتل و AMD و مقولهی معماری مجموعه دستورات SSE و AVX و FMA
کارت گرافیک 10 برابر قویتر است اما برای محاسبات موازی بهینه است
در پردازندهی اصلی، اعمال پردازشی که ماهیت موازی ندارند، بیشتر است. به این ترتیب سرعت کلاک پردازنده معمولاً 3 تا 5 گیگاهرتز (پردازندهی گرافیکی 0.6 تا 1.1 گیگاهرتز) است تا اعمال پشت سر هم را در کمترین زمان ممکن به پایان برساند. هستههای پردازشی نیز مثل کارت گرافیکهای ردهاول، در حد چند هزار عدد نیست بلکه فقط 2 الی 8 هسته وجود دارد. در واقع کارت گرافیک برای محاسبات خاصی که ذاتاً میتوانند موازی پردازش شوند، بهینه است و پردازنده که شاید یک دهم کارت گرافیک قدرت پردازشی داشته باشد، برای تردهای پردازشی کمتعداد بهینه است و به سرعت امور محوله را تکمیل میکند.
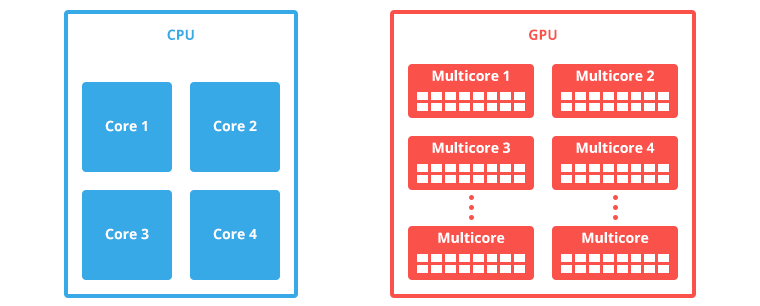
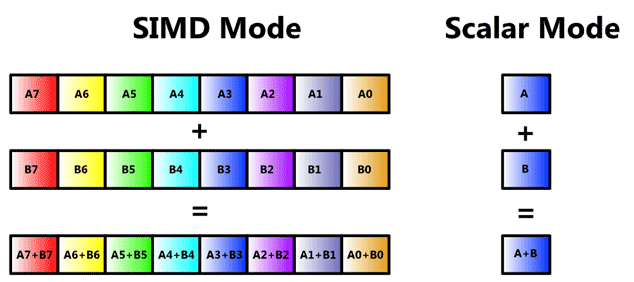
قدرت خام پردازشی در پردازندهها، به نوع مجموعه دستوراتی که کدها برای آن بهینه شدهاند، وابسته است. در حقیقت محاسبات اعشاری به صورت SIMD (مخفف Single Instruction Multiple Data) در پردازنده اجرا میشوند، یک دستور برای انجام چند محاسبهی موازی با چند دادهی اولیه. به SIMD دستورات برداری هم میگویند، مثلاً بردار X با Y جمع شده و در بردار Z ذخیره میشود. هر یک از بردارها 4 عضوی است و در واقع باید عمل جمع 8 داده در آن واحد صورت بگیرد:
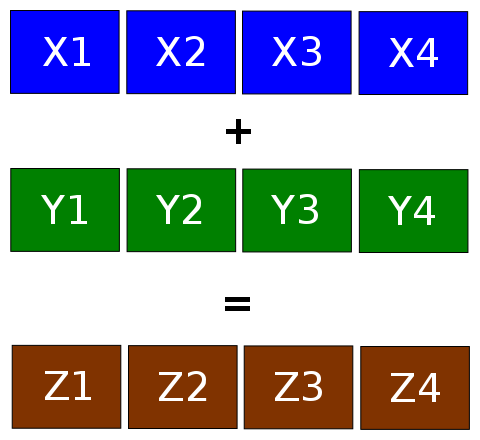
برای اجرای SIMD از اکستنشنهای جریانی SIMD یا به اختصار SSE که در حقیقت افزونهای برای معماری x86 اینتل (و AMD) است، استفاده میشود.
در پردازندههایی که از SSE پشتیبانی میکنند، یک هسته در یک سیکل کلاک، 4 عمل 32 بیتی اعشاری را انجام میدهد. بنابراین اگر سرعت هسته 4 گیگاهرتز باشد، قدرت خام هر هسته 16 گیگافلاپس است و پردازنده مجموعاً قدرت پردازشی خام 64 گیگافلاپس دارد. عدد بسیار کوچکی است چرا که کارت گرافیکهای ردهاول امروزی، 5000 گیگافلاپس معادل 5 ترافلاپس قدرت دارند.
در SSE فقط 8 رجستر 128 بیتی برای 4 محاسبهی 32 بیتی اضافه شده بود و با معرفی SSE2 امکان انجام 2 محاسبهی 64 بیتی و همینطور 8 محاسبهی عدد صحیح 16 بیتی فراهم شد.
اگر از مجموعه دستورات AVX به معنی اکستنشنهای پیشرفتهی برداری استفاده شود، قدرت پردازشی باز هم بیشتر میشود. AVX در سال 2008 به پردازندههای سندی بریج اینتل و در سال 2011 به پردازندههای بولدوزر (سری FX ایامدی) اضافه شد. تفاوت AVX با SSE در این است که رجیسترهای اضافی، 256 بیتی هستند. میتوان SIMDهای 128 بیتی سابق را بدون هیچ مشکل خاصی توسط AVX اجرا کرد.
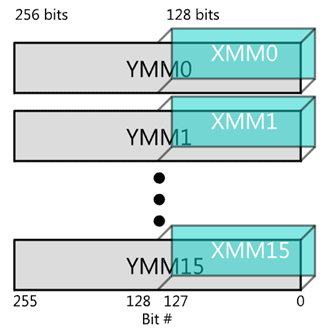
در حالت بهینه، AVX میتواند 8 عمل 32 بیتی را تنها در یک سیکل کلاک اجرا کند و حالت زیر اتفاق میافتد:
لذا با مجموعه دستورات AVX، رجیستر 128 به رجیستر 256 بیتی تبدیل میشود و قدرت محاسبات خام، دو برابر میشود.
و تفاوت دیگر: در AVX، دستورات SIMDها سه عملوند (operand) دارند. در SSE عبارت a=a+b محاسبه میشود و حاصلجمع جای a را میگیرد اما در AVX عبارت a=b+c که دارای سه عملوند است هم قابل محاسبه است و حاصلجمع مستقل از a و b است.
در AVX2 امکان استفاده از رجیسترهایی با کاربری کلی نیز فراهم شد. رجیستر 128 بیتی محاسبات صحیح، به رجیستر 256 بیتی تبدیل شده و به علاوه FMA3 (مخفف Fused Multiply–Add یا ضرب و جمع ترکیبی) سه عملوندی پشتیبانی شد. تفاوت دیگر امکان بارگذاری داده از موقعیتهای ناپیوسته در حافظه است.

AVX-512 یا AVX512 در سال 2013 به پردازندههای اینتل اضافه شده است. AVX-512 شامل اکتنشنهای متنوعی است اما پشتیبانی از AVX-512 به این معنی است که قطعاً اکستنشن AVX-512 F پشتیبانی میشود. AVX-512 F از رجیسترهای 512 بیتی برای پردازش بهینهتر بهره میگیرد.
اما ببینیم بهینه کردن فرآیند پردازشی برای استفاده بردن از SSE و AVX و FMA به چه معنی است و قدرت خام پردازشی، میتواند چند برابر شود. به جدول زیر که مقایسهی APUهای کاوری و ترینیتی با پردازندههای هسول و آیوی بریج اینتل است، دقت کنید:
| قدرت پردازشی FP32 و FP64 پردازندههای اینتل و ایامدی | |||||
|---|---|---|---|---|---|
| پلتفرم | کاوری | ترینیتی | Llano | هسول | آیوی بریج |
| Chip | 7850K | 5800K | 3870K | 4770K | 3770K |
|
سرعت پردازنده (گیگاهرتز) |
3.7 | 3.8 | 3 | 3.5 | 3.5 |
| SSE FP32 در یک سیکل کلاک | 16 | 16 | 32 | 32 | 32 |
| SSE FP64 در یک سیکل کلاک | 8 | 8 | 16 | 16 | 16 |
| AVX FP32 در یک سیکل کلاک | 16 | 16 | - | 64 | 64 |
| AVX FP64 در یک سیکل کلاک | 8 | 8 | - | 32 | 32 |
| AVX FMA FP32 در یک سیکل کلاک | 32 | 32 | - | 128 | - |
| AVX FMA FP64 در یک سیکل کلاک | 16 | 16 | - | 64 | - |
| توان پردازشی به صورت SSE FP32 | 59.2 | 60.8 | 96 | 112 | 112 |
| توان پردازشی به صورت SSE FP64 | 29.6 | 30.4 | 48 | 56 | 56 |
| توان پردازشی به صورت AVX FP32 | 59.2 | 60.8 | - | 224 | 224 |
| توان پردازشی به صورت AVX FP64 | 29.6 | 30.4 | - | 112 | 112 |
| توان پردازشی به صورت AVX FMA FP32 | 118.4 | 121.6 | - | 448 | - |
| توان پردازشی به صورت AVX FMA FP64 | 59.2 | 60.8 | - | 224 | - |
در برخی معماریها، AVX قدرت پردازش اعشاری 32 بیتی را دو برابر کرده که با توجه به افزایش اندازهی رجیسترها، منطقی و بدیهی است. استفاده از FMA به این معنی است که یک عمل اعشاری جمع و با یک عمل اعشاری ضرب ترکیب شده و همزمان اجرا میشود. بنابراین قدرت پردازشی دو برابر خواهد شد.
در نهایت قدرت پردازشی پردازندهی ردهاول Core i7-4770K بدون بهینهسازیها، 64 گیگافلاپس و با تمام بهینهسازیها که البته غیرممکن است، 448 گیگافلاپس است. 10 برابر کمتر از بهترین کارت گرافیک در دوران درخشش این مدل خاص.
اینتوتک